|
|

|

|
| e-Pub |
Section: New Results
Learning and statistical models
A Universal Catalyst for First-order Optimization
Participants : Hongzhou Lin, Julien Mairal, Zaid Harchaoui.
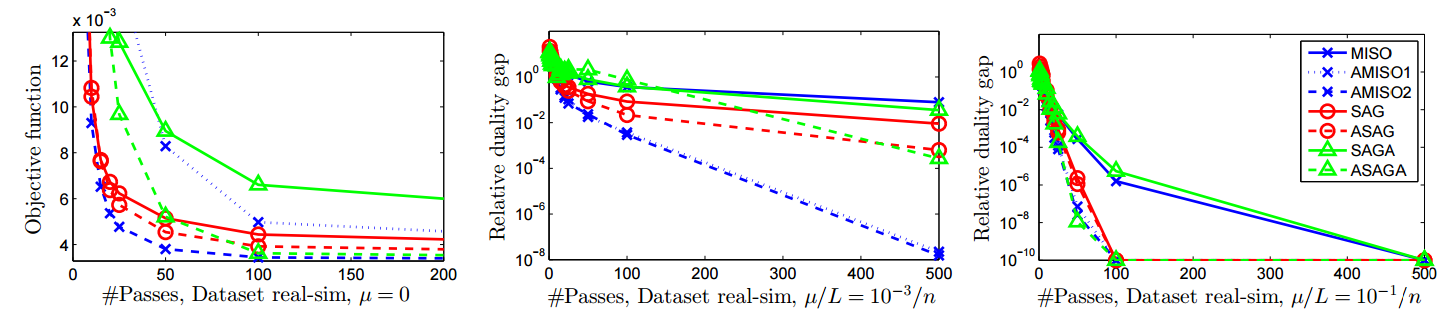
In this paper [16] , we introduce a generic scheme for accelerating first-order optimization methods in the sense of Nesterov, which builds upon a new analysis of the accelerated proximal point algorithm. Our approach consists of minimizing a convex objective by approximately solving a sequence of well-chosen auxiliary problems, leading to faster convergence. This strategy applies to a large class of algorithms, including gradient descent, block coordinate descent, SAG, SAGA, SDCA, SVRG, Finito/MISO, and their proximal variants. For all of these methods, we provide acceleration and explicit support for non-strongly convex objectives. In addition to theoretical speed-up, we also show that acceleration is useful in practice, as illustrated in Figure 4 , especially for ill-conditioned problems where we measure significant improvements.
|
Incremental Majorization-Minimization Optimization with Application to Large-Scale Machine Learning
Participant : Julien Mairal.
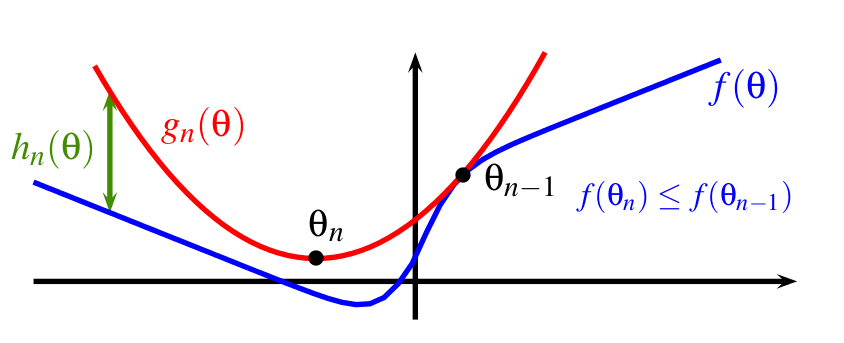
In this paper [7] , we study optimization methods consisting of iteratively minimizing surrogates of an objective function, as illustrated in Figure 5 . We introduce a new incremental scheme that experimentally matches or outperforms state-of-the-art solvers for large-scale optimization problems typically arising in machine learning.
|
Coordinated Local Metric Learning
Participants : Shreyas Saxena, Jakob Verbeek.
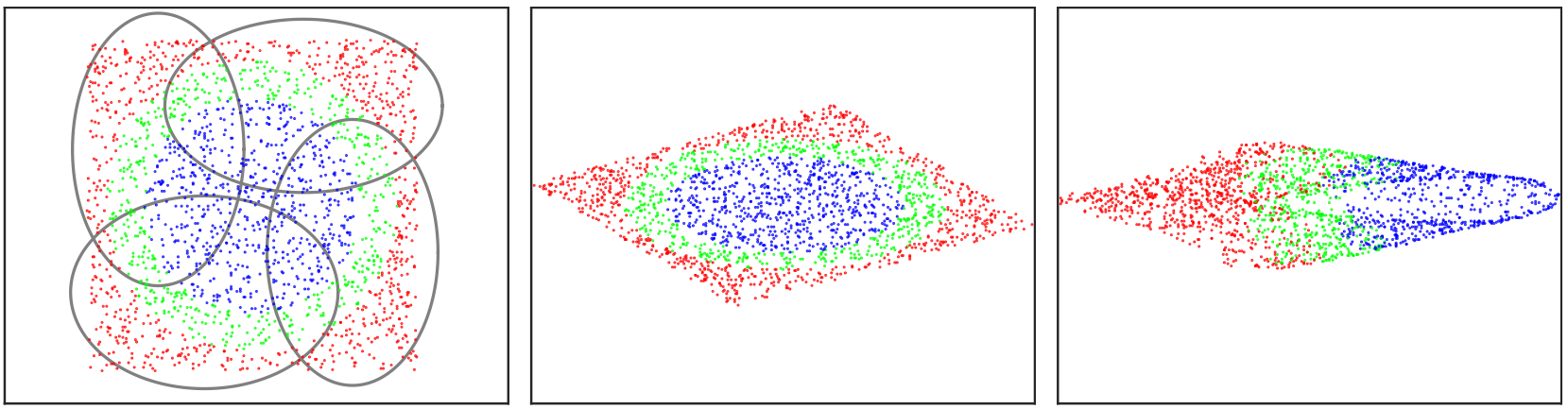
Mahalanobis metric learning amounts to learning a linear data projection, after which the metric is used to compute distances. In [20] , we develop local metric learning techniques which allow more flexible metrics, not restricted to linear projections, see 6 . Most of these methods partition the data space using clustering, and for each cluster a separate metric is learned. Using local metrics, however, it is not clear how to measure distances between data points assigned to different clusters. In this paper we propose to embed the local metrics in a global low-dimensional representation, in which the metric can be used. With each cluster we associate a linear mapping that projects the data to the global representation. This global representation directly allows computing distances between points regardless to which local cluster they belong. Moreover, it also enables data visualization in a single view, and the use of -based efficient retrieval methods. Experiments on the Labeled Faces in the Wild dataset show that our approach improves over previous global and local metric learning approaches.
|
A convex formulation for joint RNA isoform detection and quantification from multiple RNA-seq samples
Participants : Elsa Bernard [Institut Curie, Ecoles des Mines-ParisTech] , Laurent Jacob [CNRS, LBBE Laboratory] , Julien Mairal, Jean-Philippe Vert [Institut Curie, Ecoles des Mines-ParisTech] .
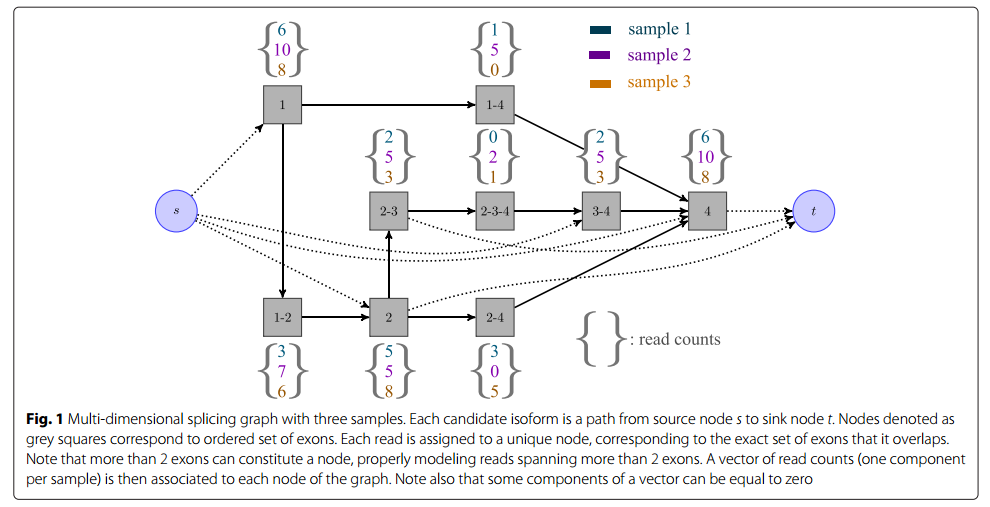
Detecting and quantifying isoforms from RNA-seq data is an important but challenging task. The problem is often ill-posed, particularly at low coverage. One promising direction is to exploit several samples simultaneously. In this paper [4] , we propose a new method for solving the isoform deconvolution problem jointly across several samples. We formulate a convex optimization problem that allows to share information between samples and that we solve efficiently, as illustrated in Figure 7 . We demonstrate the benefits of combining several samples on simulated and real data, and show that our approach outperforms pooling strategies and methods based on integer programming. Our convex formulation to jointly detect and quantify isoforms from RNA-seq data of multiple related samples is a computationally efficient approach to leverage the hypotheses that some isoforms are likely to be present in several samples. The software and source code are available at http://cbio.ensmp.fr/flipflop .
|
Adaptive Recovery of Signals by Convex Optimization
Participants : Zaid Harchaoui, Anatoli Juditsky [Univ. Grenoble] , Arkadi Nemirovski [Georgia Tech] , Dimitry Ostrovsky [Univ. Grenoble] .
In [13] , we present a theoretical framework for adaptive estimation and prediction of signals of unknown structure in the presence of noise. The framework allows to address two intertwined challenges: (i) designing optimal statistical estimators; (ii) designing efficient numerical algorithms. In particular, we establish oracle inequalities for the performance of adaptive procedures, which rely upon convex optimization and thus can be efficiently implemented. As an application of the proposed approach, we consider denoising of harmonic oscillations
Semi-proximal Mirror-Prox for Nonsmooth Composite Minimization
Participants : Niao He [Georgia Tech] , Zaid Harchaoui.
In [28] , we propose a new first-order optimisation algorithm to solve high-dimensional non-smooth composite minimisation problems. Typical examples of such problems have an objective that decomposes into a non-smooth empirical risk part and a non-smooth regularisation penalty. The proposed algorithm, called Semi-Proximal Mirror-Prox, leverages the Fenchel-type representation of one part of the objective while handling the other part of the objective via linear minimization over the domain. The algorithm stands in contrast with more classical proximal gradient algorithms with smoothing, which require the computation of proximal operators at each iteration and can therefore be impractical for high-dimensional problems. We establish the theoretical convergence rate of Semi-Proximal Mirror-Prox, which exhibits the optimal complexity bounds, for the number of calls to linear minimization oracle. We present promising experimental results showing the interest of the approach in comparison to competing methods.